
- 21
- 이니스프리
- 조회 수 1347
안녕하세요?
JLPT 시험을 앞두고 저번에 제르엘 님께서 알려주신 네이버 사전의 JLPT 레벨 기능을 이용하고 있습니다.
단어만 크롤링해서 막판에 암기하려고 하는데요.
이상하게 일부 한자만 깨지는 현상이 발생하네요 ㅠㅠ
from requests_html import HTMLSession
from bs4 import BeautifulSoup
number = 0
while number <= 14:
url = 'https://ja.dict.naver.com/jlpt/level-5/parts-0/p' + str(number) + '.nhn'
session = HTMLSession()
r = session.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
list = soup.select('ul.lst li')
for word in list:
jn = word.select_one('span.jp').text
kr = word.select_one('span.bot_txt').text
print(jn + ' : ' + kr + '\n')
with open('jlptn5.txt', 'a', encoding='utf-8') as f:
f.write(jn + ' : ' + kr + '\n')
session.close
number +=1 완벽한 크롤링 스크립트는 아니고, 시험 전이라 마음이 급해서 아직 일부만 작성하였습니다.
(단어 뜻이 잘려서 크롤링됩니다 ㅠㅠ)
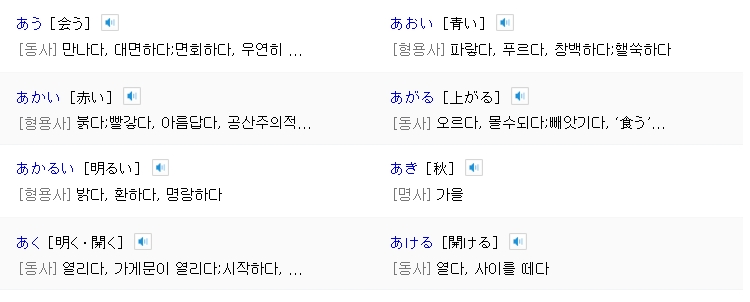
원래화면:
출처 - https://ja.dict.naver.com/jlpt/level-5/parts-0/p1.nhn
CMD:

TXT 파일:
あう[?う] : [동사]만나다, 대면하다;면회하다, 우연히 ...
あおい[?い] : [형용사]파랗다, 푸르다, 창백하다;핼쑥하다
あかい[赤い] : [형용사]붉다;빨갛다, 아름답다, 공산주의적...
あがる[上がる] : [동사]오르다, 몰수되다;빼앗기다, ‘食う’...
あかるい[明るい] : [형용사]밝다, 환하다, 명랑하다
CMD와 파일을 보면, 첫번째 단어와 두번째 단어의 첫 글자인 한자가 나오지 않는 것을 확인할 수 있습니다.
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
헤더를 보면 해당 페이지의 인코딩은 UTF-8이 맞는 것 같은데 말이죠.
인코딩이라는 것이 잘못되면 전체가 다 깨져서 나오는 것으로 이해하고 있는데요.
이렇게 일부 한자만 깨지는 것은 어떻게 해결해야 되는 것인가요??
구글에 '인코딩 한자 깨짐' 등으로 검색해도 나오지 않네요 ㅠㅠ
인코딩의 문제가 아니라 윈도우에서 한자 폰트를 추가로 설치해서 해결해야 되는 것인가요??
혹시나 자바스크립트 렌더링의 문제인가 해서 r.html.render()를 추가해봤지만 결과는 동일하네요 ㅠㅠ
그럼 즐거운 불금과 뜻깊은 주말 되세요!
스포어 회원님들께 항상 감사드립니다 ^^
+) 윈도우7과 우분투 16.04 LTS에 한글만 설치된 환경에서 테스트했습니다.
작성자

댓글 21


https://ja.dict.naver.com/entry/jk/JK000000000330.nhn 을 비롯한 각 단어의 개별 페이지를 for 문으로 파싱해도 마찬가지로 깨지네요 ㅠㅠ
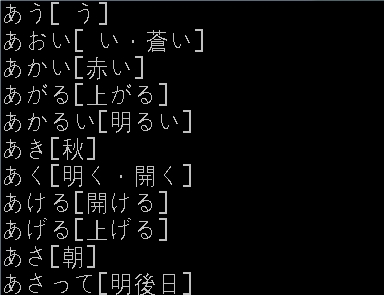

깨진 한자들을 보니 전부 한국 한자와 모양이 다른 신자체 한자네요. 일단 시스템 언어와 로케일을 일본어로 바꿔보세요. 제가 제시할 수 있는 해결책은 여기까지가 아닐까 싶네요.
에에에~ 그렇군요!!! 감사합니다 ^-^
제가 시험이 1주일 남았는데 아직도 한자를 잘 몰라서 신자체라는 것이 존재하는지 처음 알았네요~ ㅎㄷㄷ
말씀하신대로 언어와 로케일을 변경하고 다시 시도해보겠습니다!
그럼 제르엘 님께서도 즐거운 주말 되세요~

죠가사키 미카... 이런 스티커는 본 적이 없었는데 혹시 어디 스티커인가요 ㅋㅋㅋ
에에에~ 저는 그냥 평범한 손그림인줄 알고 올렸는데 신데마스 캐릭터였군요?! ㅎㄷㄷ
아마도 루리웹에서 받아놓은 짤로 기억하는데요~
구글링해보니 웃대의 댓글에 이 짤이 올라와있네요!
https://band.us/band/60446539/post/122745
여기에 이 짤을 포함해서 유사한 짤들이 올라와있는데 제 PC에서는 움짤로 안 보이네요 ㅠㅠ
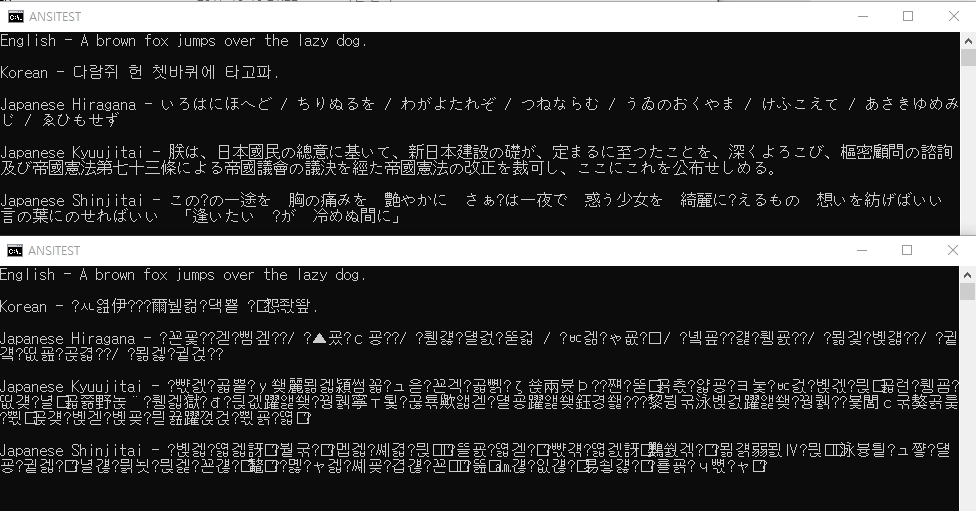
참고로 위가 CP949 인코딩이며 아래가 UTF-8 인코딩을 CP949로 읽어들인 것입니다. 구자체 한자들은 보통 한국 한자와 동일한 자형을 사용하기 때문에 문자가 깨지지 않지만, 신자체 한자인 恋, 変, 涙 등이 여지없이 깨져나가는 것을 보실 수 있습니다. 다만 인코딩이 꼬여 UTF-8 인코딩이 변환 없이 CP949 인코딩으로 저장됐다면 위 화면보다는 아래 화면이 보일 가능성이 더 높을 겁니다. 만약 UTF-8 인코딩이 CP949 인코딩으로 변환되어 저장되었다면 위 화면과 같은, 일부 글자가 누락된 페이지를 보실 수 있을 겁니다. 물론 제가 문자 인코딩이나 크롤링에 대해서 아는 건 전무한 수준이니 적당히 걸러 들으시길 바랍니다.
해당 배치 파일의 코드는 다음과 같습니다. 저장 과정 중 잘려나간 신자체 텍스트를 복구한 버전이며, 따라서 이를 다시 CP949 인코딩으로 저장하면 恋, 変, 涙가 ?로 깨져 보이게 됩니다. 아예 저장 단계부터 이 세 글자는 ?로 대치된 채 파일에서 사라집니다. 일본어 히라가나 예문은 이로하 노래, 구자체 예문은 일본 헌법, 신자체 예문은 美に入り彩を穿つ라는 제목의 신데마스 곡에서 따왔습니다.
@echo off
title ANSITEST
echo English - A brown fox jumps over the lazy dog.echo.echo Korean - 다람쥐 헌 쳇바퀴에 타고파.
echo.echo Japanese Hiragana - いろはにほへど / ちりぬるを / わがよたれぞ / つねならむ / うゐのおくやま / けふこえて / あさきゆめみじ / ゑひもせずecho.echo Japanese Kyuujitai - 朕は、日本國民の總意に基いて、新日本建設の礎が、定まるに至つたことを、深くよろこび、樞密顧問の諮詢及び帝國憲法第七十三條による帝國議會の議決を經た帝國憲法の改正を裁可し、ここにこれを公布せしめる。echo.echo Japanese Shinjitai - この恋の一途を 胸の痛みを 艶やかに さぁ恋は一夜で 惑う少女を 綺麗に変えるもの 想いを紡げばいい 言の葉にのせればいい 「逢いたい 涙が 冷めぬ間に」pause>nul

허걱 신데마스 노래였군요~!
제르엘 님께 항상 많이 배우네요!!
다음주 JLPT N5에 합격하면 제르엘 님 덕분이네요 ㅎㅎ
감사합니다 ^-^ 굿밤 되세요~
N5 그렇게 어렵지는 않습니다. 제가 중2 때 대충 공부해서 간당간당하게 딸 수 있었던 정도예요.
오오~ 역시 제르엘 님께서는 일본어를 잘 하시네요!!
틈틈이 공부했다고 생각했는데 아직 가타카나도 못 읽어서 큰 일이네요~ ㅠㅠ
어느 정도 수준이냐면... 志摩 'リン'을 못 읽네요 -_-;;;
しぶや りん은 읽을 수 있습니다
사진은 '일본어 속성문법'이라는 책이고 N4~5용 교재라고 하던데요~
오늘 '나'형용사까지 이 책 인강을 들었는데 대략 어디까지 보고 시험장에 들어가야 될까요? ㄷㄷ
유닛 30 정도까지는 봐야될까요??
저야말로 갱생해야겠습니다 ㅜㅜ

오오~ 상세한 설명 감사드립니다!!
저도 인코딩에 대해서 무지해서 말이죠 ㅠㅠ
네이버 사전 페이지 소스에서 인코딩이 UTF-8인 것을 확인했습니다.
말씀해주신대로 CP949임을 가정하여 테스트해봤는데 일단 이 문제는 아닌 것 같네요.
우분투에서 일본어 언어팩을 설치하려고 했으나 디펜던시 중에 일부가 꼬여서 안 되네요 ㅠㅠ
제 PC에 설치된 윈도우 버전은 자체적으로 로케일을 변환할 수 없구요 -_-;;;
다른 PC에 파이썬을 설치해서 해결해보겠습니다~
그럼 굿밤 되시고 다음주도 화이팅입니다!
다시 한 번 감사드려요 :)

깔려 있던 윈도우가 싱글 랭귀지 버전이었을까요...? 일반 소비자용 버전은 로케일을 자유자재로 바꿀 수 있었을텐데요.

제 윈도우7은 Professional인데도 불구하고 두번째 설정 자체가 없네요 ㅠㅠ
시리얼을 2012년경에 지인에게 구매했는데 정확히 어떤 버전인지 모르겠네요.
다른 PC에서 다시 시도해보려구요~
굿밤 되세요!!
") humit
humit 
일본어용 폰트를 설치해서 적용해보시겠어요?
일단 windows 10에서는 CMD에서 문제 없이 잘 출력되고 있습니다.
바쓰신데 확인해주셔서 감사합니다!
제가 컴알못이라서 찾지 못하는 것인지는 모르겠지만... 제 윈도우7에는 제어판에서 언어 추가설치를 할 수 없네요 ㅠㅠ
https://support.microsoft.com/ko-kr/help/14236/language-packs 여기를 보면 다음과 같이 나오는데요.
Windows 업데이트를 사용합니다. Windows의 Ultimate 또는 Enterprise 버전을 실행하는 경우 Windows 업데이트를 사용하여 언어 팩을 다운로드할 수 있습니다.
저는 윈도우7 Professional를 설치해서 아마도 해당사항이 없는 것 같네요 ㅠㅠ
굿밤 되시고 곧 기말고사 기간이실텐데 화이팅입니다~! ^^
humit
→ 이니스프리
언어팩 설치를 의미한게 아니라 그냥 일본어를 지원하는 폰트를 설치해서 적용해보라는 의미였습니다.
https://www.freejapanesefont.com/
앗.. 랭귀지팩이 아니라 폰트를 설치하라는 말씀이셨군요~
집에 들어가서 시도해보겠습니다!
바쁘신데 번번이 감사합니다 ^-^
말씀해주신 사이트의 첫번째 폰트를 설치한 후 재부팅하여 다시 시도해봤으나 아쉽게도 해당 글자는 계속 안 나오네요 ㅠㅠ
이번 시험은 5일도 남지 않아서 촉박하니 일단 다른 단어장으로 공부를 하고, 어차피 윈도우 7 지원기간이 내년 1월에 종료되니 조만간 윈도우 10을 구매하겠습니다.
조언해주셔서 감사합니다!! 굿밤 되세요~ ^^
humit
→ 이니스프리
폰트 설치한 다음 메모장으로 열 때 해당 폰트로 지정을 했는데도 안나오는 건가요??
그러면 저도 방법을 확실히 모르겠네요 ㅎㅎ...
앗 그렇게 해야되는 것이군요! 제가 멍청하게 삽질을 했네요~ ㅠㅠ
말씀하신대로 폰트를 지정해서 열거나, 한컴워드로 TXT 파일을 여니깐 안 깨지고 잘 보이네요~
덕분에 프린터로 출력해서 지금부터 이걸로 공부하겠습니다 ^-^
번번이 감사합니다!!
 슬기
슬기
우분투에서 테스트해보니 동일한 한자가 깨지는 현상이 있네요 ㅠㅠ