
안녕하세요?
구글 커스텀 서치가 제공되고 있지만, 아쉽게도 제한되는 부분이 많아서 구글 이미지 서치 결과를 받아오는 일종의 커스텀 API를 만들어보았습니다.
Requests로 구현할 수 있으면 좋겠지만, 자바스크립트로 렌더링되는 부분이 많고 아직 제 실력이 부족한 관계로 부득이 Selenium을 사용했습니다.
GET 요청에 대한 응답을 바로 BeautifulSoup에 넣는 것은 구글에서 난독화(?)로 막아놓은 것 같아서 div.rg_meta에 접근하는 방법으로 구현하였습니다.
작성한 함수에 검색어와 검색할 이미지 수를 입력하면, (1) 타이틀, (2) 이미지 URL, (3) 이미지 확장자, (4) 본문 URL을 반환합니다.
머신러닝이나 커뮤니티 사이트 운영을 위해 특정 테마 또는 확장자의 이미지를 다량으로 수집해야 하는 경우에 유용할 것 같습니다.
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
import time, json
options = Options()
#options.headless = True
driver = webdriver.Firefox(options=options)
driver.implicitly_wait(5)
def search(keyword, number):
driver.get('https://www.google.com/webhp?hl=국가코드') # 검색할 국가코드를 넣으세요(ex. 미국 en, 일본 ja).
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, '/html/body/div/div[4]/form/div[2]/div[1]/div[1]/div/div[2]/input')))
elem = driver.find_element_by_xpath('/html/body/div/div[4]/form/div[2]/div[1]/div[1]/div/div[2]/input')
elem.clear()
elem.send_keys(keyword)
elem.submit() # 입력한 검색어를 제출합니다.
WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.XPATH, '/html/body/div[6]/div[3]/div[5]/div/div/div[1]/div/div/div[1]/div/div[2]/a')))
driver.find_element_by_xpath('/html/body/div[6]/div[3]/div[5]/div/div/div[1]/div/div/div[1]/div/div[2]/a').click() # 이미지 탭으로 이동합니다.
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located)
images = []
while len(images) < number:
images = driver.find_elements_by_xpath('//div[contains(@class,"rg_meta")]')
height1 = driver.execute_script("return document.body.scrollHeight") # Body의 height를 측정합니다.
time.sleep(0.5)
driver.execute_script("window.scrollBy(0, 1000000)") # 브라우저 스크롤을 내립니다.
time.sleep(1) ##### Ajax를 기다리는 부분을 EC로 어떻게 표현해야 적절할지 모르겠습니다 ㅠㅠ #####
height2 = driver.execute_script("return document.body.scrollHeight")
time.sleep(1)
if height1 == height2: # 스크롤을 더 이상 내릴 수 없는 경우를 처리합니다.
try:
time.sleep(1) ##### Ajax를 기다리는 부분을 EC로 어떻게 표현해야 적절할지 모르겠습니다 ㅠㅠ #####
driver.find_element_by_xpath('//*[@id="smb"]').click() # 결과 더보기가 나오면 클릭합니다.
time.sleep(1) ##### Ajax를 기다리는 부분을 EC로 어떻게 표현해야 적절할지 모르겠습니다 ㅠㅠ #####
WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located)
except:
print('Not enough images.') # 더 이상 이미지를 찾을 수 없으면 루프를 탈출합니다.
break
images = driver.find_elements_by_xpath('//div[contains(@class,"rg_meta")]') # 검색결과를 출력합니다.
cnt = 1
for img in images:
img_title = json.loads(img.get_attribute('innerHTML'))["pt"] # 타이틀
img_url = json.loads(img.get_attribute('innerHTML'))["ou"] # 이미지 URL
img_type = json.loads(img.get_attribute('innerHTML'))["ity"] # 확장자
img_link = json.loads(img.get_attribute('innerHTML'))["ru"] # 본문 URL
print(cnt, img_title, img_url, img_type, img_link, sep=' : ')
cnt += 1
if __name__ == "__main__":
search('검색어', 검색할 이미지수)위 소스에 대해 알고리즘 측면에서 문제가 없는지 테스트해보았습니다.
1. 검색된 이미지수보다 적은 이미지수를 입력한 경우
search('site:ruliweb.com "게임기" "구매" "후기"', 1000) 이렇게 입력하고 테스트해봤습니다.
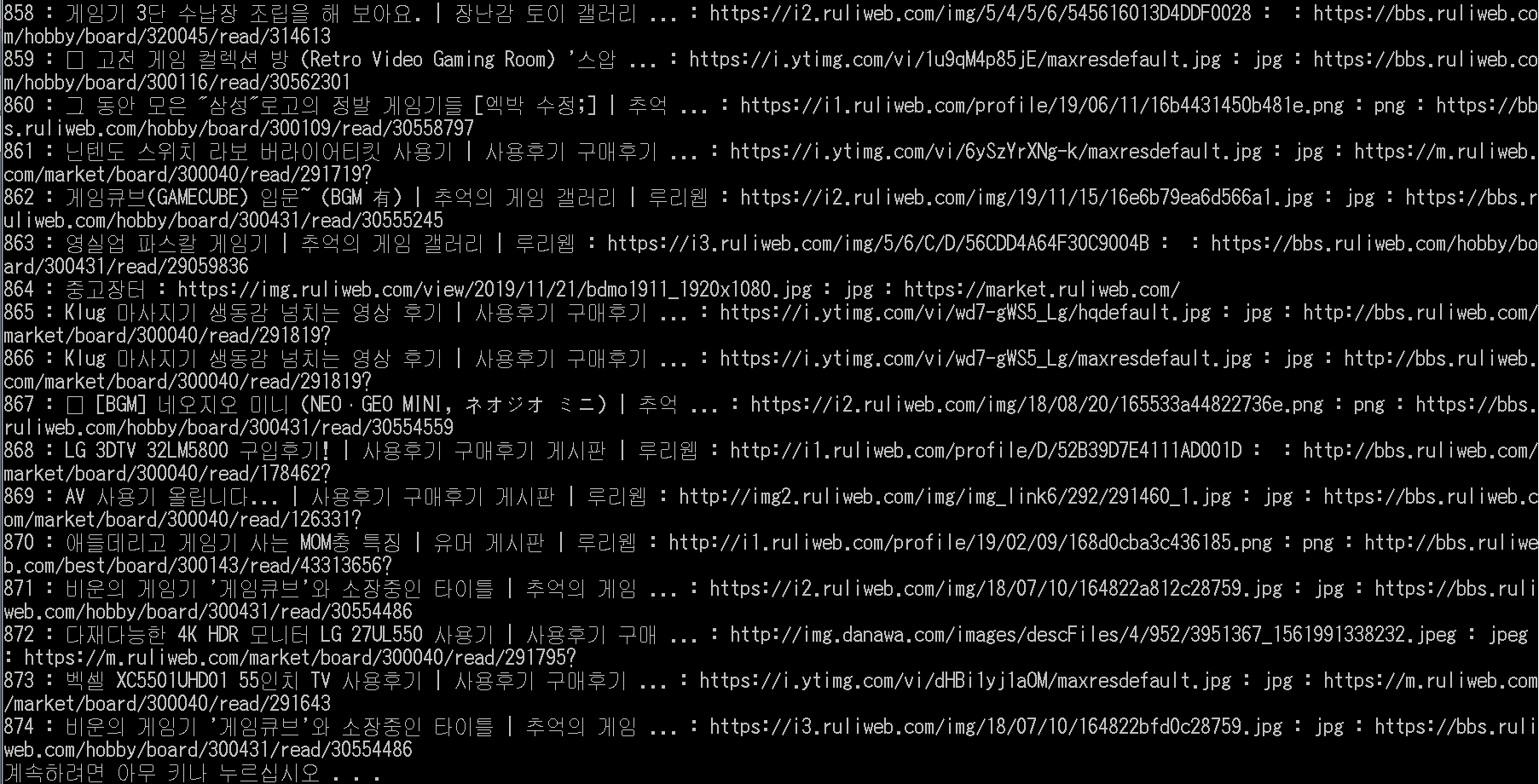
브라우저 스크롤과 '결과 더보기' 클릭도 잘 되고, 일단 아직까지는 특별한 문제를 발견하지 못했습니다.
2. 검색된 이미지수가 입력된 이미지수보다 많은 경우
search('site:ruliweb.com "방문" "후기" "엽기떡볶이" "강원도" -외국인', 1000)
강원도에서 엽기떡볶이에 방문하는 내국인은 별로 없는 것 같네요 ㄷㄷ

이 경우 또한 별다른 문제를 발견하지 못했습니다.
3. 애매한(?) 숫자를 입력한 경우
search('site:ruliweb.com "게임기" "구매" "후기"', 100)
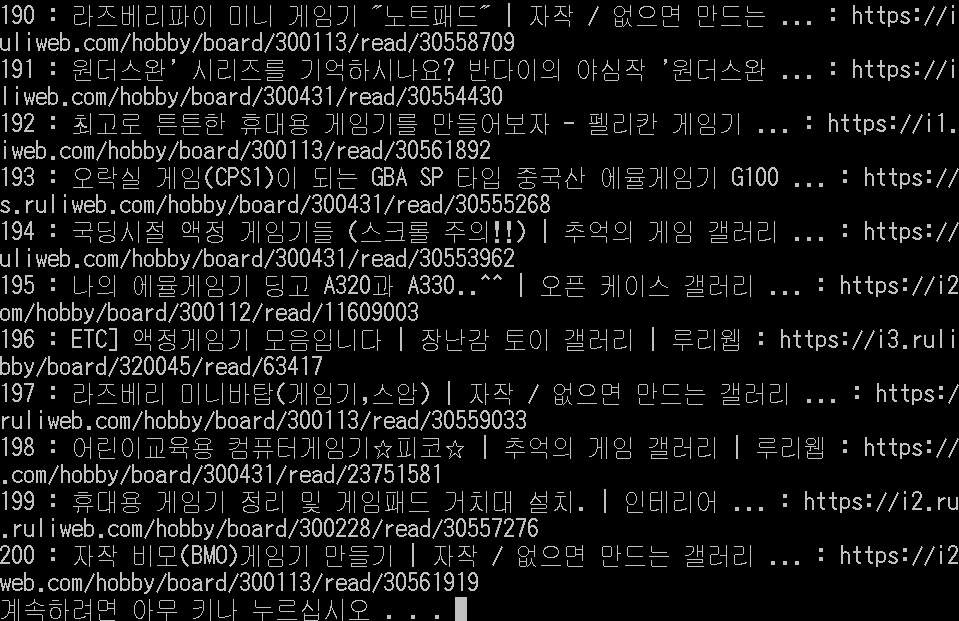
100개를 입력했는데 200개에서 끊기네요 ㄷㄷ
스크롤해서 찾은 이미지가 원하는 이미지수를 넘어가면 루프를 탈출하도록 했는데, 스크롤 한 번에 찾아지는 이미지수가 상당히 많기 때문에 발생하는 현상 같습니다.
정확한 이미지 개수를 반환받기를 원하는 경우에는 출력하는 단계 등에서 적절히 자를 필요가 있겠습니다.
결론적으로 스크립트에 군더더기도 많고 완전히 깔끔하게 구동되지는 않지만, 2019년 12월 현재 큰 문제 없이 작동하여 어느 정도 원하는 결과를 얻을 수 있었습니다.
스크립트에 각주로 ##### Ajax를 기다리는 부분을 EC로 어떻게 표현해야 적절할지 모르겠습니다 ##### 라고 달아놓은 부분에 대해서는 좀 더 공부를 해야될 것 같네요 ㅠㅠ
예전에는 Selenium으로 구현하면 쉽고, Requests로 구현하면 어렵다고 막연히 생각했는데요.
여러 사이트에서 크롤링 연습을 해보니 공부를 하면 할수록 둘 다 어렵다고 느껴지네요 ㅠㅠ
스포어에는 고수님들도 많이 계시는데 저의 허접한 스크립트를 읽어주셔서 감사합니다 ^-^
그럼 저녁식사 맛있게 드시고 편안한 저녁 되세요!


 TVJ
TVJ") humit
humit